
Motivation
I’ve spent a lot of time figuring out how to get data from Salesforce using Python. Along the way, I faced many challenges and learned a lot. Now, I want to share what I’ve learned to help others. This post is a guide to extracting data from Salesforce with Python. I’ll explain things step by step, give examples, and offer tips to make it easier for you. My goal is to help you get the data you need from Salesforce for your own projects.
Simple Salesforce
There are multiple ways of querying Salesforce data with Python. I prefer using Simple Salesforce because, as the name suggests, it simplifies the data extraction process.
It’s worth noting that the Official documentation | Simple Salesforce may have some missing functions. So, I recommend also checking the GitHub readme for additional information.
To begin, you’ll need to instantiate the Salesforce object as follows:
from simple_salesforce import Salesforce
sf = Salesforce(
username="your_username",
password="your_password",
consumer_key="your_consumer_key",
consumer_secret="your_consumer_secret",
)Please ensure that you replace all the placeholder strings with the appropriate values.
Querying and __getattr__
This is the simplest query you can execute:
sf.Account.get('003e0000003GuNXAA0')Note that we’re querying the Account entity, and to do so, you need to access the Account attribute from the sf object.
This adds a bit of complexity to the pipeline. However, you can use the __getattr__("name") method to programmatically access attributes based on the entity name.
For example, both of these statements do the same thing:
sf.Account.get('003e0000003GuNXAA0')
sf.__getattr__("Account").get('003e0000003GuNXAA0')You’ll find that this approach can be applied throughout this post.
Querying options
There are various methods available for retrieving data from Salesforce using the Simple Salesforce library. Here’s a detailed overview of each:
| get | query | query_all | query_all_iter | bulk.query_all | bulk2.query | |
|---|---|---|---|---|---|---|
| Batch Querying | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ |
| No need of pagination | - | ❌ | ✔️ | ✔️ | ✔️ | ✔️ |
| Iterable (no memory errors) | - | ❌ | ❌ | ✔️ | ⚠️ | ✔️ |
| Result as python object | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Includes deleted | ❌ | ✔️ | ✔️ | ✔️ | ✔️ | ❌ |
| Can query compound data (*) | - | ✔️ | ✔️ | ✔️ | ❌ | ❌ |
(*) More info about compound data in section 4.
You can also view the query time of each method using the same query.
I would recommend using either query_all_iter.
Entity get
You can use the get method to retrieve a single entity:
sf.Account.get('003e0000003GuNXAA0')While useful for retrieving a single value, it’s not suitable for exporting a large number of rows.
query
You can use sf.query to retrieve multiple rows at once.
However, there’s a limit on the number of records you can fetch. If your query exceeds this limit, you’ll need to use sf.query_more.
Here’s an example:
sf.query("SELECT Id, Name FROM Account")
# The previous call will have: "nextRecordsUrl" : "/services/data/v26.0/query/01gD0000002HU6KIAW-2000
sf.query_more("01gD0000002HU6KIAW-2000")You can find more information about this in the Queries | Simple Salesforce documentation.
I don’t suggest using this option since there are easier methods available that don’t require dealing with the sf.query_more option.
query_all
This method is similar to query, but it returns all results as a Python object:
sf.query_all("SELECT Id, Name FROM Account")The problem with this approach is that you can easily encounter Out of Memory (OOM) errors when attempting to load a large amount of data into memory.
query_all_iter
This works similarly to the previous methods, but the result is an iterator.
This allows you to process each row one at a time and avoid Out of Memory (OOM) errors.
Here’s how it works:
query = "SELECT Id, Name FROM Account"
data = sf.query_all_iter(query, include_deleted=True)
for row in data:
process(row)Under the hood, it fetches records in bulk using the sf.query and sf.query_more functions.
You may notice that the first row takes longer to retrieve than the rest when querying a large amount of data.
This is the method I recommend using.
Bulk
There are two ways of querying with bulk: the regular one and the lazy operation.
The regular method works similarly to query_all_iter, allowing you to iterate over the results without encountering OOM errors.
The lazy method, on the other hand, is similar to query_all, fetching everything in one batch.
Here’s how the regular call works:
query = "SELECT Id, Name FROM Account"
# generator on the results page
data = sf.bulk.Account.query_all(query)
# the generator provides the list of results for every call to next()
for row in data:
process(row)And here’s how to call it lazily:
query = "SELECT Id, Name FROM Account"
# generator on the results page
data = sf.bulk.Account.query_all(query, lazy_operation=True)
# the generator provides the list of results for every call to next()
for chunk in data:
process(chunk)Note that chunk contains all rows.
This function is consistently 2 to 3 times faster than query_all_iter.
However, since it cannot extract compound fields, it would make extraction more complex, as you would need to recreate all that logic in the data lake.
Bulk2
Finally, there’s also the bulk2 option.
query = "SELECT Id, Name FROM Account"
results = sf.bulk2.Account.query(
query, max_records=50000, column_delimiter="COMM", line_ending="LF"
)
for i, data in enumerate(results):
with open(f"results/part-{1}.csv", "w") as bos:
bos.write(data)With this method, the iterator returns batches of the requested size (max_records).
However, one important caveat is that the result is a Python string similar to a CSV.
This means extra work for parsing the result, such as handling problems with separators, encoding issues, extra I/O operations, etc.
During testing, I observed around a 20% performance improvement compared to bulk.
However, given that it’s not a significant improvement, I believe it’s not worth the effort.
Avoiding Timeouts and Out of Memory Errors
After extracting data from Salesforce for several months, I’ve discovered a couple of tricks to make the pipeline more resilient. These include:
- Exporting data in chunks.
- Splitting the query into batches.
Additionally, I’ve found it beneficial to always query only the data that has been updated. You can find more information about this approach in Self-Healing Pipelines.
Chunks
Exporting data in chunks is a straightforward method. For tables that may contain a large amount of data, I prefer exporting records in smaller, manageable chunks. The chunk size can be adjusted based on query speed observations. Typically, I set the chunk size so that each chunk takes a similar amount of time to process (e.g., 5 minutes).
Here’s an example using a function that can be called iteratively:
from time import time
from loguru import logger
DATA = sf.query_all_iter(query, include_deleted=True)
CHUNK_NUM = 0
ALL_DONE = False
def fetch_one_chunk(max_rows_per_chunk=100_000):
t0 = time()
out = []
for i, row in enumerate(DATA):
if (CHUNK_NUM == 0) and (i == 0):
logger.info(
f"First row extracted in {round(time() - t0, 2)} seconds"
)
out.append(row)
if max_rows_per_chunk and (i + 1 == max_rows_per_chunk):
break
else:
logger.info(f"There are no more records")
ALL_DONE = True
CHUNK_NUM += 1
return outYou can then use this function within a loop to process each chunk:
MAX_ITERATIONS = 200
for chunk_num in range(MAX_ITERATIONS):
data = fetch_one_chunk()
export_data(data)This approach helps to:
- Avoid Out of Memory (OOM) errors.
- Provide progress updates for long-running queries that may fail.
Batches
Attempting to query a large amount of data in one go can sometimes lead to timeouts.
Based on my experience, if the first row cannot be extracted within 2 minutes, simple_salesforce will raise an exception.
To prevent such timeouts, I recommend splitting the query into multiple batches.
This is achieved by defining the max_days_per_batch parameter and then performing multiple queries, each with a specified batch length.
Here’s a function to generate batches:
from datetime import timedelta
from math import ceil
from loguru import logger
def get_dates_batches(min_date, max_date, max_days_per_batch=None):
if (min_date is None) or (max_date is None):
logger.info(f"No need for batches since one date is None")
return [(min_date, max_date)]
logger.debug(
f"Removing timezone info so that both 'min_date' and 'max_date' are compatible"
)
min_date = min_date.replace(tzinfo=None)
max_date = max_date.replace(tzinfo=None)
logger.info(f"After cleaning values: {min_date=}, {max_date=}")
# Check if batches are needed
if not max_days_per_batch:
logger.info(f"No need for batches for this entity (max_days_per_batch=None)")
return [(min_date, max_date)]
# Calculate batches
total_days = (max_date - min_date) / timedelta(days=1)
n_batches = ceil(total_days / max_days_per_batch)
chunks = []
start_date = min_date
for x in range(n_batches):
end_date = min(start_date + timedelta(days=max_days_per_batch), max_date)
chunks.append([start_date, end_date])
start_date += timedelta(days=max_days_per_batch)
return chunksTypes of Fields
Fields (or Columns) in Salesforce are flexible and can contain different types of data. I classify fields into three types:
- Primitive fields: These provide information about the entity itself.
- Reference fields: These are links to other tables, similar to a join.
- Compound fields: These are formulas based on other fields, including fields from referenced tables.
Primitive Fields
Primitive fields are the basic type of fields, providing information about the entity itself.
For example, in the User table, primitive fields might include:
firstname: The user’s first name (string).age: The user’s age (integer).
Reference Fields
Reference fields are links to other tables and behave similarly to a join in SQL. The two important parts of reference fields are:
referenceTo: Indicates which entity the field refers to.relationshipName: The name assigned to the relationship.
Here are examples of reference fields:
| name | type | referenceTo | relationshipName |
|---|---|---|---|
| CreatedById | reference | [User] | CreatedBy |
| LastModifiedById | reference | [User] | LastModifiedBy |
| Delegation__c | reference | [Delegation__c] | Delegation__r |
| User__c | reference | [User] | User__r |
Compound Fields (Calculated Fields)
Compound fields are populated at query time based on a formula.
For example, in the User table, we might have firstName and lastName as primitive fields, with fullName defined as FirstName & ’ ’ & LastName. More information about compound fields can be found in Compound fields.
Compound fields can use information from referenced entities!
Consider an example where the Order table has fields such as CreatedById, LastModifiedById, and User__c.
We could have a calculated field called fullName with the formula User__r.FirstName & ' ' & User__r.LastName.
When extracting data, compound fields are risky because:
Changes in the referenced table do not modify the LastModifiedDate from the main table.
In the example above, modifying User.FirstName would result in a different fullName, but the Order table’s LastModifiedDate would remain unchanged.
This can lead to incorrect data extraction.
Retrieving Field Information
You can use sf.Entity.describe() to retrieve field definitions as a dictionary.
This can be transformed into a Pandas DataFrame for easier viewing:
import pandas as pd
data = sf.__getattr__("entity_name").describe()
df = pd.DataFrame(data["fields"]).set_index("name")Alternatively, you can use Pydantic to define the attributes you want:
from pydantic import BaseModel
from typing import List, Optional
class Column(BaseModel):
name: str
type: str
calculated: bool
calculatedFormula: Optional[str]
referenceTo: Optional[List[str]]
relationshipQuerying with External Changes
After writing this post I discovered that I can simply use SystemModstamp for getting all changes done to an entity.
Here is the original content for reference, but I strongly suggest you query with SystemModstamp instead.
The problem
Compound fields can be calculated based on external entities.
However, an update on the related entity does not change the LastModifiedDate of the main entity.
This poses a challenge when querying data.
Let’s illustrate this problem with an example where we want to query the Delegation entity, which depends on the User entity:
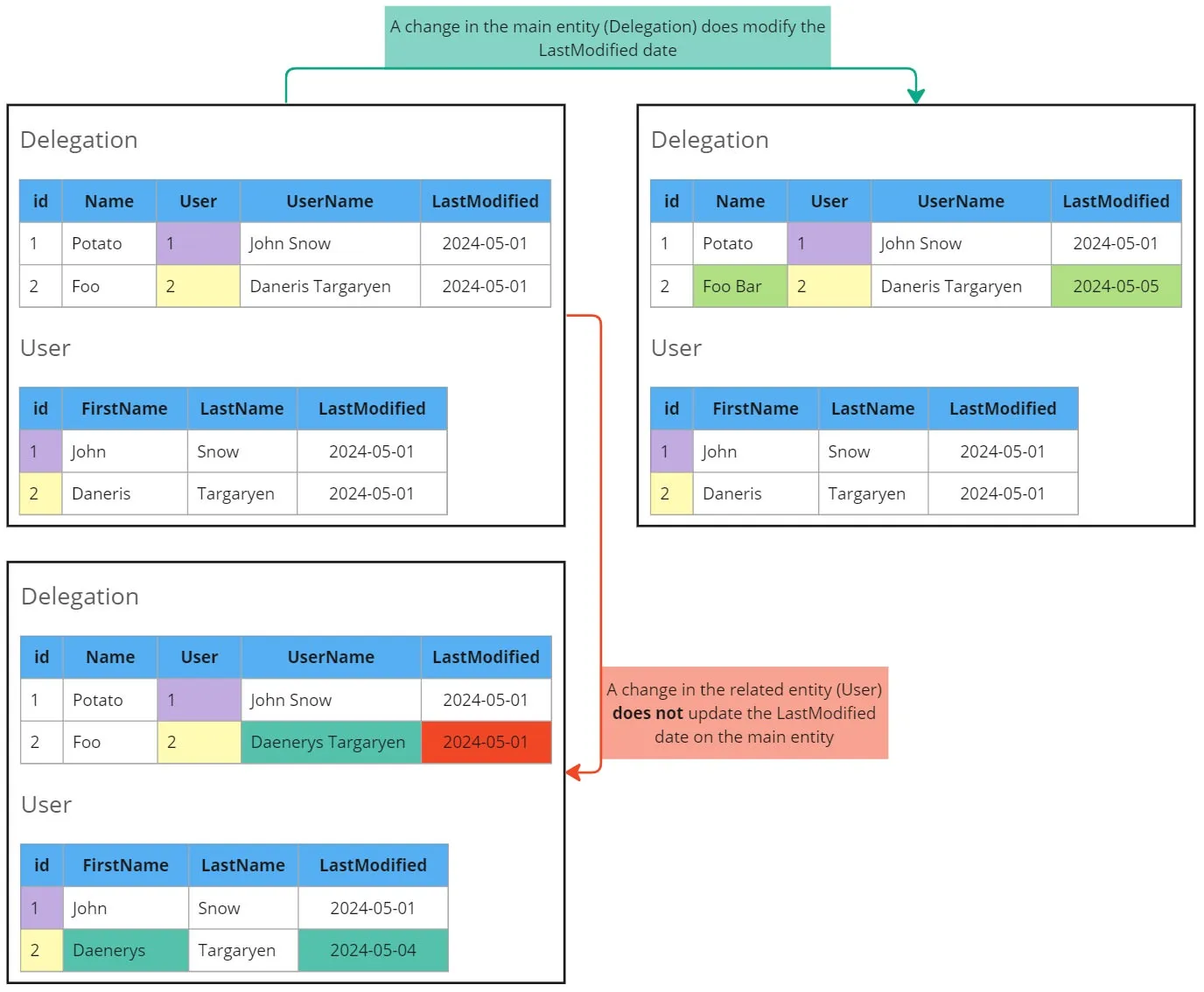
The solution
To address this issue, we need to filter the LastModifiedDate of both entities when querying.
To automate this process, we can retrieve all fields of type reference and check if their relationshipName is used in any calculatedFormula.
If so, we include that related entity in the query.
For example, if we have the following fields:
| name | calculated | calculatedFormula | type | referenceTo | relationshipName |
|---|---|---|---|---|---|
| Id | False | id | |||
| CreatedById | False | reference | [User] | CreatedBy | |
| LastModifiedById | False | reference | [User] | LastModifiedBy | |
| Delegation__c | False | reference | [Delegation__c] | Delegation__r | |
| User__c | False | reference | [User] | User__r | |
| UserName__c | True | User__r.FirstName & ’ ’ & User__r.LastName | string | ||
| IsDeleted | False | boolean | |||
| Name | False | string | |||
| CreatedDate | False | datetime | |||
| LastModifiedDate | False | datetime | |||
| SystemModstamp | False | datetime |
In this example, CreatedBy, LastModifiedBy, and Delegation__r are not used in any calculatedFormula. However, User__r is used in the formula for UserName__c, so we need to query the User entity as well.
So in that case we would do a query like:
SELECT
Id,
CreatedById,
LastModifiedById,
Delegation__c,
User__c,
UserName__c,
IsDeleted,
Name,
CreatedDate,
LastModifiedDate,
SystemModstamp
FROM Delegation
WHERE (LastModifiedDate >= {min_date} AND LastModifiedDate < {max_date})
OR (User__r.LastModifiedDate >= {min_date})You should replace {min_date} and {max_date} with datetimes with the format %Y-%m-%dT%H:%M:%SZ (do not include any " or ').
Deciding Date Ranges
In regular runs, I query data from the last extraction (max(LastUpdateDate) from the table where the export will be stored) up until the current datetime (datetime.now()).
More information about this approach can be found in Self-Healing Pipelines.
Between the query creation and the execution, some time may pass.
To ensure we don’t lose records, we need to set max_date as a filter and discard records that are modified afterwards.
For example:

When dealing with external entities, we only include the min_date since that date won’t be used for the next execution to determine the next min_date.
Automatically Detecting Related Entities
To automate the detection of related entities, we can search for relationshipName entries in an entity and check if they are found in the calculatedFormula of any other field.
This can be achieved using regular expressions:
import re
REGEX_RELATION = r"\b{relationship}\.\b"
def get_referenced_entities(entity):
fields = sf.__getattr__(entity).describe()["fields"]
cols = [Column(**x) for x in fields] # More info in section 4.4
formulas = [
col.calculatedFormula
for col in cols
if col.calculated and (col.calculatedFormula is not None)
]
out = {}
for col in cols:
if col.type != TYPE_REFRENCE:
continue
regex = re.compile(REGEX_RELATION.format(relationship=col.relationshipName))
for formula in formulas:
if regex.search(formula):
# In 'Lead' there is 'OwnerId' which is throwing errors
if len(col.referenceTo) > 1:
logger.warning(
f"Excluding {col=} since it has multiple 'referenceTo'"
)
continue
out[col.relationshipName] = "LastModifiedDate"
if out:
logger.info(f"{entity=} has references with '{out}'")
return outThis function retrieves all fields of type reference, extracts their relationshipName, and checks if it appears in any calculatedFormula.
If found, it adds the related entity to the query.
Data size
With this new approach, you will download rows whenever:
- They have changed.
- An external entity used in a formula has changed.
In the second scenario, you don’t have an easy way to distinguish if the change is in a field used in the formulas or in other fields. This means that you will consistently download more data than is really needed.
In general, this is not a problem, but in some cases, it can lead to too much data being downloaded.
For example, let’s imagine we are querying orders and there is a calculated field that uses the products entity.
The orders table is very large, but there are no massive changes to entries there.
However, we have very few products, so any change in one of them will lead to many orders being downloaded.
That can greatly slow down the extractions since a lot of data will be extracted.
Be careful with the amount of data you need to extract when doing compound queries.
It could be even worse. For instance, we have an automated process that updates all products at night.
That means we need to download all orders daily.
The solution we found here was to disable some external entities (such as products in orders) and remember not to rely on fields in the orders table that derive from product, since we don’t have a way to guarantee their accuracy.
Other alternatives could be:
- Letting the long process run and assuming the cost.
- Triggering the pipeline more frequently, which could lead to smaller batches.
Bonus: Final code
Here you can see the final code that is explained during the post
Salesforce connector class
This is the code for querying salesforce:
sf_connector.py
import re
from datetime import datetime
from datetime import timedelta
from time import time
from typing import List
from typing import Optional
from pydantic import BaseModel
from simple_salesforce import Salesforce
from simple_salesforce.exceptions import SalesforceMalformedRequest
from prefect import get_run_logger
TYPE_REFRENCE = "reference"
REGEX_RELATION = r"\b{relationship}\.\b"
FILTER_COL = "LastModifiedDate"
MARGIN_HOURS = 6
SF_DT_FORMAT = "%Y-%m-%dT%H:%M:%SZ"
class Column(BaseModel):
name: str
type: str
calculated: bool
calculatedFormula: Optional[str]
referenceTo: Optional[List[str]]
relationshipName: Optional[str]
class SalesForceConnector:
def __init__(
self,
secret,
entity,
filter_col=None,
max_rows_per_chunk=None,
query_referenced_entities=True,
):
self.logger = get_run_logger()
self.logger.debug(f"Initializing Salesforce Connector for '{entity}'")
self._sf = Salesforce(
username=secret["username"],
password=secret["password"],
consumer_key=secret["consumer_key"],
consumer_secret=secret["consumer_secret"],
)
self.entity = entity
self.filter_col = filter_col
self.max_rows_per_chunk = max_rows_per_chunk
self.query_referenced_entities = query_referenced_entities
self.data = None
def _get_raw_fields(self, entity=None):
if entity is None:
entity = self.entity
return self._sf.__getattr__(self.entity).describe()["fields"]
def get_all_columns(self, entity=None):
raw_fields = self._get_raw_fields(entity)
return [x["name"] for x in raw_fields if x["name"] != "attributes"]
def get_date_columns(self, entity=None):
raw_fields = self._get_raw_fields(entity)
return [x["name"] for x in raw_fields if x["type"] in ["date", "datetime"]]
def _get_filter_col(self, entities):
"""
Since all referenced entities have 'LastModifiedDate' as the filter column
right now we just return that. In the future we might want to inspect the entity
and then see what column can be used for filtering
"""
msg = "References to multiple entities not allowed"
assert len(entities) == 1, msg
return FILTER_COL
def get_referenced_entities(self):
cols = [Column(**x) for x in self._get_raw_fields()]
formulas = [
col.calculatedFormula
for col in cols
if col.calculated and (col.calculatedFormula is not None)
]
out = {}
for col in cols:
if col.type != TYPE_REFRENCE:
continue
regex = re.compile(REGEX_RELATION.format(relationship=col.relationshipName))
for formula in formulas:
if regex.search(formula):
# In 'Lead' there is 'OwnerId' which is throwing errors
if len(col.referenceTo) > 1:
self.logger.warning(
f"Excluding {col=} since it has multiple 'referenceTo'"
)
continue
out[col.relationshipName] = self._get_filter_col(col.referenceTo)
if out:
self.logger.info(f"{self.entity=} has references with '{out}'")
return out
def _get_referenced_entities_filter(self, min_date):
out = ""
for entity, col in self.get_referenced_entities().items():
out += f" OR ({entity}.{col} >= {min_date:{SF_DT_FORMAT}})"
return out
def _construct_query(self, min_date=None, max_date=None):
cols = ",".join(self.get_all_columns())
query = f"SELECT {cols} FROM {self.entity}"
filter_col = self.filter_col
if not filter_col:
return query
date_cols = self.get_date_columns()
msg = f"You can only use a date column for filtering ({date_cols})"
assert filter_col and (filter_col in date_cols), msg
msg = "'max_date' cannot be None. It should default to 'datetime.now()'"
assert max_date is not None, msg
if min_date:
query += f" WHERE ({filter_col} >= {min_date:{SF_DT_FORMAT}}"
query += f" AND {filter_col} < {max_date:{SF_DT_FORMAT}})"
if self.query_referenced_entities:
query += self._get_referenced_entities_filter(min_date)
if not min_date:
query += f" WHERE ({filter_col} < {max_date:{SF_DT_FORMAT}})"
query += f" ORDER BY {filter_col} ASC"
return query
def query_lazy(
self, min_date=None, max_date=None, query=None, include_deleted=True
):
"""
Queries salesforce for the given entity.
The dates can be `datetime` or `date` and it will work for both.
It will store a generator called `self.data`.
Then it is expected to call `sf.fetch_in_chunks`
"""
if not query:
query = self._construct_query(min_date, max_date)
# Prepare values for 'fetch_one_chunk'
self.logger.info(f"Querying all (lazy) with {query=}")
self.data = self._sf.query_all_iter(query, include_deleted=include_deleted)
self.chunk_num = 0
self.all_done = False
def _fetch_one_chunk(self):
"""Internal function to extract a chunk"""
t0 = time()
out = []
for i, row in enumerate(self.data):
if (self.chunk_num == 0) and (i == 0):
self.logger.info(
f"First row extracted in {round(time() - t0, 2)} seconds"
)
out.append(row)
if self.max_rows_per_chunk and (i + 1 == self.max_rows_per_chunk):
break
else:
self.logger.info(f"There are no more records for '{self.entity}'")
self.all_done = True
return out
def fetch_one_chunk(self):
"""Fetches records in chunks. Must be called after `sf.query_lazy`"""
if self.data is None:
self.logger.error(
"You must first call 'sf.query_lazy' before fetching chunks"
)
return None
if self.all_done:
return []
chunk_msg = f"[Chunk {self.chunk_num + 1}]"
self.logger.info(f"{chunk_msg} Querying {self.entity=}")
t0 = time()
try:
out = self._fetch_one_chunk()
except SalesforceMalformedRequest as e:
self.logger.error(
f"{chunk_msg} Query failed after {round(time() - t0, 2)} seconds: {e}"
)
raise e
msg = (
f"✔ {chunk_msg} {len(out)} records extracted "
f"for {self.entity=} in {round(time() - t0, 2)} seconds"
)
# If possible show first and last value to have a sense of the progress
if out and self.filter_col:
first_val = out[0][self.filter_col][:19] # Crop to seconds
last_val = out[-1][self.filter_col][:19] # Crop to seconds
msg += f" ({first_val=}, {last_val=})"
self.logger.info(msg)
self.chunk_num += 1
return outSaleforce export
This is the python file that calls the queries and exports them:
sf_export.py
from datetime import datetime
from pathlib import Path
from typing import List
import yaml
from prefect import get_run_logger
from prefect import task
from pydantic import BaseModel
from pydantic import computed_field
from pyspark.sql import functions as F
from pyspark.sql import types as T
from common.dates import get_dates_batches
from common.secrets import get_secret
from common.spark import get_spark_session
from sf_connector import SalesForceConnector
from sf_connector import SF_DT_FORMAT
def get_tables():
"""[Out of scope] Retrieves a list of the tables to export"""
raise NotImplementedError
def infer_min_datetime(spark, tablename, filter_col):
"""[Out of scope] This should give the `max(filter_col)` from the destinationt table"""
raise NotImplementedError
def export_records(
spark, records, cols, tablename, files_per_partition, filter_col=None, max_date=None
):
"""[Out of scope] Here you should defined how to create a dataframe and export it"""
raise NotImplementedError
def process_one_table(spark, secret, table, params):
logger = get_run_logger()
sf = SalesForceConnector(
secret,
table.entity,
table.filter_col,
max_rows_per_chunk=table.max_rows_per_chunk,
query_referenced_entities=params.query_referenced_entities,
)
cols = sf.get_all_columns()
# Infer 'min_date' if needed
min_date = params.min_date
if not min_date:
min_date = infer_min_datetime(spark, table.table_out, table.filter_col)
# Since querying everything sometimes gives a timeout
# we will do batches (which will query in multiple chunks)
batches = get_dates_batches(min_date, params.max_date, table.max_days_per_batch)
if len(batches) > 1:
logger.info(f"Processing in {len(batches)} batches to avoid timeouts")
for batch_num, (start_date, end_date) in enumerate(batches):
if len(batches) > 1:
logger.info(f"Starting batch {batch_num + 1}")
# Prepare generator
sf.query_lazy(start_date, end_date)
# Extract in chunks
for chunk_num in range(params.max_iterations_per_table):
records = sf.fetch_one_chunk()
if len(records) == 0:
if chunk_num == 0:
logger.warning(
f"There are no records for '{table.entity}' WHERE "
f"'{table.filter_col}' BETWEEN '{start_date}' AND '{end_date}'. "
"Skipping dataframe creation and writing."
)
break
export_records(
spark,
records,
cols,
table.table_out,
files_per_partition=params.files_per_partition,
filter_col=table.filter_col,
max_date=params.max_date,
)
else:
logger.error(
f"Extractions didn't finish for '{table.entity}' after extracting "
f"{params.max_iterations_per_table * table.max_rows_per_chunk} rows "
f"[{params.max_iterations_per_table} iterations of {table.max_rows_per_chunk} rows]"
)
def main(params):
logger = get_run_logger()
spark = get_spark_session(params.entrypoint)
secret = get_secret(params.secret_name)
tables = get_tables()
for i, table in enumerate(tables):
logger.info(f"[Table {i + 1}/{len(tables)}] Processing '{table.table_out}'")
process_one_table(spark, secret, table, params)
spark.stop()There are some functions that are not defined (such as get_tables, infer_min_datetime and export_records) since they are out of the scope of this post.
Conclusion
In this guide, we’ve explored various techniques for building robust data extraction pipelines from Salesforce, covering strategies to handle timeouts, avoid memory errors, and efficiently query related entities. By implementing these approaches, you can ensure reliable and scalable data retrieval processes tailored to your organization’s needs.
As you embark on your Salesforce data extraction journey, don’t hesitate to experiment with the techniques discussed here and adapt them to your specific use cases. Remember, continuous refinement and optimization are key to building resilient and efficient pipelines.
If you found this guide helpful, consider giving it a thumbs up or leaving a comment below to share your thoughts and experiences. Your feedback is valuable and can help improve future content.
Happy data extracting!

