
Motivation
Amazon S3 is a powerful, scalable storage solution integral to many workflows. However, storage costs can quickly accumulate, especially when managing large datasets. After migrating some of our jobs from EMR to ECS, S3 storage emerged as our largest expense.
By analyzing our storage usage and implementing targeted strategies, we successfully reduced our S3 costs to one-third, as illustrated in the plot below.
This guide outlines how to export an S3 Inventory and implement Lifecycle Policies to track and optimize your storage expenses effectively.
Categorizing S3 Costs
Discover S3 Costs with Cost Explorer
The first step is to examine your AWS costs by service using the Cost Explorer. This allows you to identify which service to target for cost reduction. In our case, after optimizing EMR costs, S3 became the next clear objective:
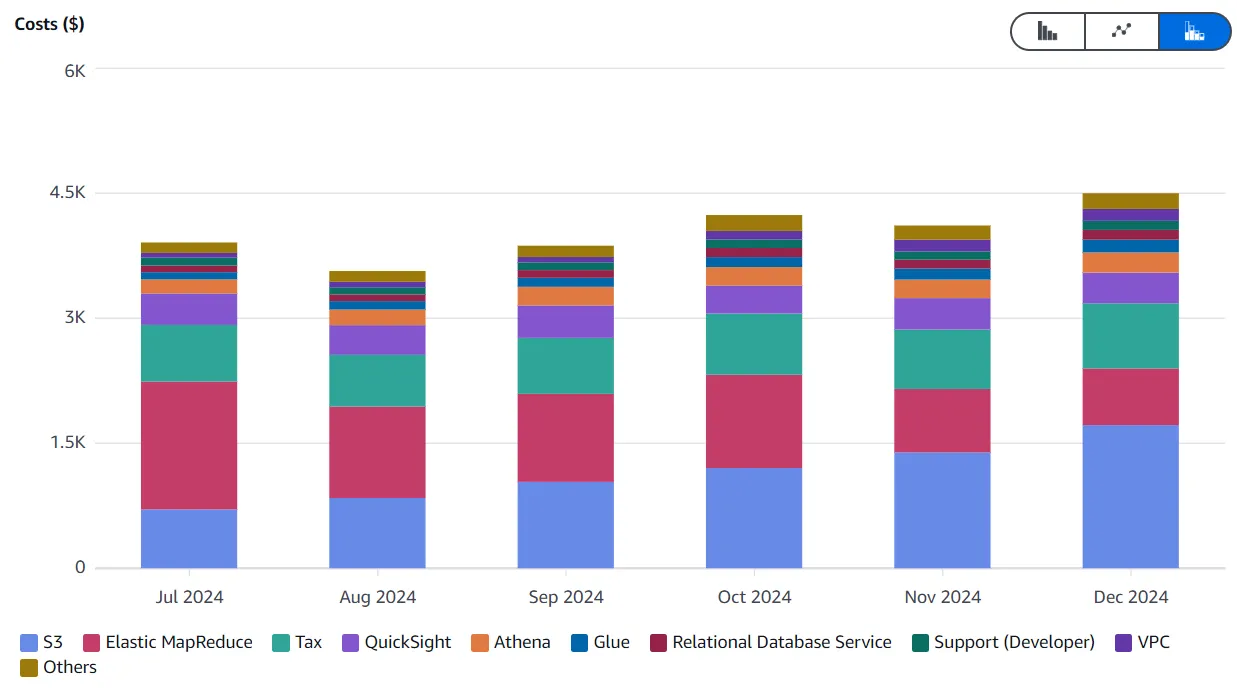
Focus on reducing costs for the AWS service with the largest expense. Target S3 only if it’s the primary cost driver.
Once you’ve identified S3 as your focus, analyze your S3 expenses by usage type:
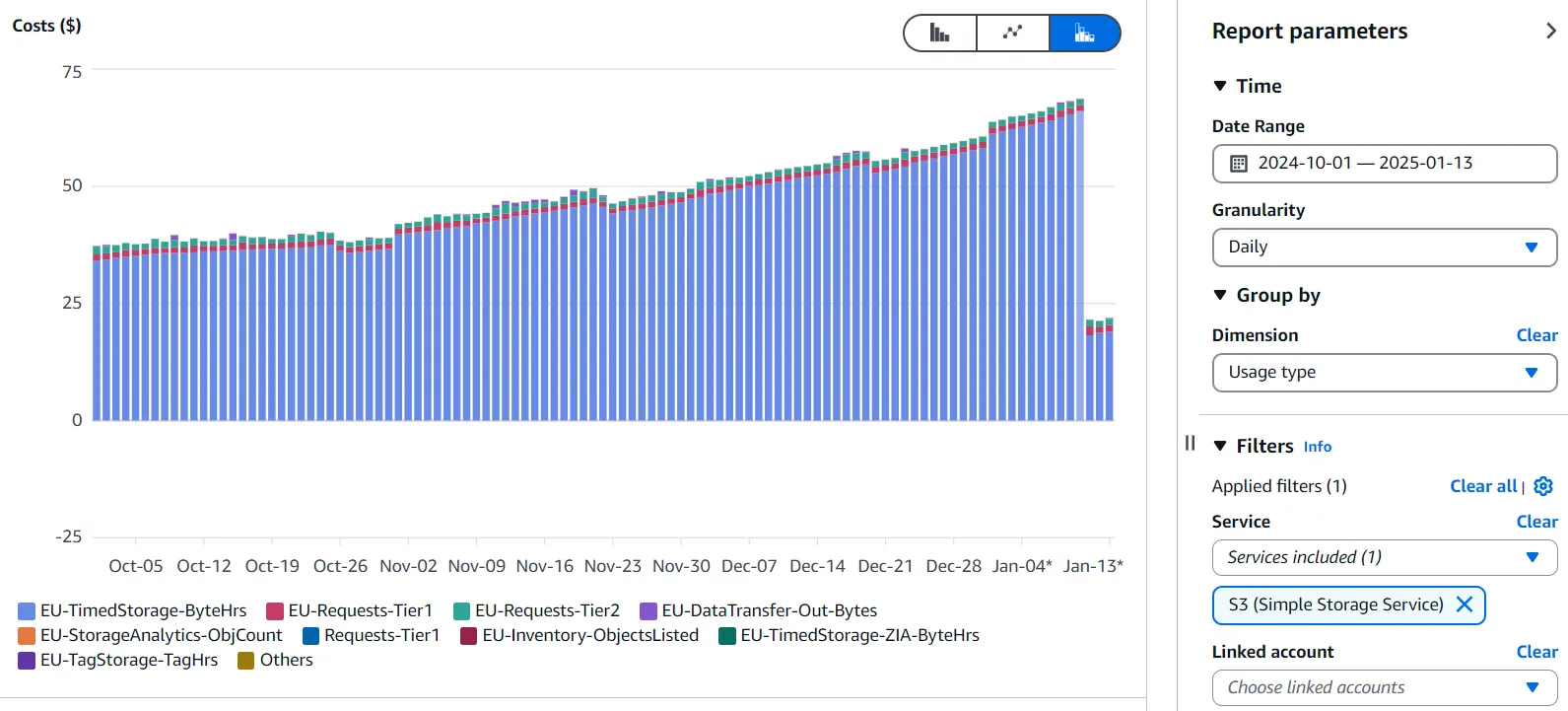
In our case, most costs stemmed from storage. However, in some organizations, high request costs may dominate, often due to numerous small files in a data lake.
If you’re incurring high S3 request costs, check out Solving the Problem with Small Files in the Data Lake for strategies to address this issue.
Create an S3 Inventory Configuration
S3 Inventory is a feature in Amazon S3 that generates scheduled reports containing a comprehensive list of objects in a bucket, along with their metadata. This helps you analyze and manage storage efficiently.
Steps to Set Up S3 Inventory:
-
Access the S3 Console: Log in to the AWS Management Console and navigate to the S3 service.
-
Select Your Bucket: Choose the bucket for which you want to create an inventory report.
-
Go to Management: In the bucket’s dashboard, select the Management tab and scroll down to the Inventory section.
-
Create Inventory Configuration:
- Click Create Inventory Configuration.
- Provide a unique name for your inventory.
- Specify the destination bucket where the inventory report will be delivered.
-
Select Report Content:
- Choose the frequency of the report: Daily or Weekly.
- Select the file format. For large datasets, export it as
parquetfor optimized storage and processing. - Specify the fields to include. At a minimum, include object
size,storage class, andlast modifieddate.
-
Review and Save:
- Review your configuration.
- Save it by clicking Create.
Notes on Destination Path:
The destination path will include additional folders automatically. For example, if your destination path is s3://villoro/s3_inventory for a bucket named villoro and inventory name villoro_inventory, the final path will be s3://villoro/s3_inventory/villoro/villoro_inventory/.
The first report will be available within 48 hours, and subsequent reports will be generated based on the frequency you selected.
Accessing the S3 Inventory
The S3 Inventory follows a unique structure. Reports are stored at destination_path/bucket_name/inventory_name/. The structure includes:
- Timestamp Folders: Contain a
manifest.jsonlisting theparquetfiles for that extraction. - Data Folder: Contains the data files from all exports.
- Hive Folder: Includes symlinks to the timestamped folders for easier querying.
Example Structure:
- s3://villoro/s3_inventory/villoro/villoro_inventory/
├── 2025-01-09T01-00Z/
│ ├── manifest.json
│ └── manifest.checksum
├── 2025-01-12T01-00Z/
│ ├── manifest.json
│ └── manifest.checksum
├── data/
│ ├── 469e11b1-730b-487b-9110-e0fac5cb4237.parquet
│ ├── ...
│ └── 91ee5bf8-c053-4993-b698-ba07009b9060.parquet
└── hive/
├── dt=2025-01-09-01-00/
│ └──symlink.txt
└── dt=2025-01-12-01-00/
└──symlink.txtExample Manifest File:
{
"sourceBucket" : "villoro",
"destinationBucket" : "arn:aws:s3:::villoro",
"version" : "2016-11-30",
"creationTimestamp" : "1736384401000",
"fileFormat" : "Parquet",
"fileSchema" : "message s3.inventory { required binary bucket (STRING); required binary key (STRING);}",
"files" : [ {
"key" : "s3_inventory/villoro/villoro_inventory/data/469e11b1-730b-487b-9110-e0fac5cb4237.parquet",
"size" : 120112,
"MD5checksum" : "f0731733165f367e93fa4a51ecc28edb"
} ]
}Extracting Data from the Inventory
To create a standard Iceberg table from the non-conventional folder structure of the S3 inventory, we need to process the manifest files, extract the corresponding Parquet data, and then structure it into a usable table. Removing source data after processing is also recommended to optimize storage.
Creating an S3 Inventory Table
The main steps involve:
- Reading Manifest Files: Extract Parquet file paths from each manifest to identify the files corresponding to a specific inventory extraction.
- Processing Data: Read the extracted Parquet files and consolidate the data into a unified table.
- Exporting Data: Export the consolidated data into an Iceberg table for further analysis.
- Cleanup: Remove source data after successful processing to free up storage.
This can be done with:
import json
from datetime import datetime
import awswrangler as wr
import pandas as pd
from prefect import flow
from prefect import task
from prefect import get_run_logger
from ecs_northius.common import glue
from ecs_northius.common import parameters
BUCKET_DE = "nt-data-engineering-eu-west-1-742407267173-pro"
PREFIX_INVENOTRY = "s3_inventory/{bucket}/{inventory}"
PATH_INVENTORY = f"s3://{BUCKET_DE}/{PREFIX_INVENOTRY}"
INVENTORIES = {
"de_inventory": BUCKET_DE,
"bronze_inventory": "ct-bronze-eu-west-1-742407267173-pro",
"silver_inventory": "ct-silver-eu-west-1-742407267173-pro",
}
DATABASE = "nt_bronze__metadata"
TABLE = "s3_inventory"
S3 = boto3.client("s3")
def get_all_files(inventory, bucket):
logger = get_run_logger()
uri = PATH_INVENTORY.format(inventory=inventory, bucket=bucket)
logger.info(f"Reading files in {uri=}")
return wr.s3.list_objects(uri)
def get_ts_from_manifest_path(manifest_file):
date_str = manifest_file.split("/")[-2]
return datetime.strptime(date_str, "%Y-%m-%dT%H-%MZ")
def get_data_files_from_manifest(manifest_file):
logger = get_run_logger()
logger.info(f"Reading manifest {manifest_file=}")
bucket, filename = manifest_file.replace("s3://", "").split("/", 1)
manifest = S3.get_object(Bucket=bucket, Key=filename)["Body"].read()
logger.debug("Parsing manifest")
return json.loads(manifest)["files"]
def read_and_export_data(inventory, bucket, data_files, reported_at):
logger = get_run_logger()
dfs = []
logger.info(f"Reading {len(data_files)} files for {inventory=}")
for file in data_files:
# The replace is to fix an error in config
key = file["key"].replace(f"{bucket}/{bucket}", bucket)
uri = f"s3://{BUCKET_DE}/{key}"
logger.debug(f"Reading parquet {uri=}")
dfs.append(wr.s3.read_parquet(uri))
df = pd.concat(dfs)
df["bucket"] = bucket
df["reported_at"] = reported_at
glue.write_iceberg(df, DATABASE, TABLE) # This uses `wr.athena.to_iceberg`
def get_bucket_and_prefix(s3_path):
if not s3_path.startswith("s3://"):
raise ValueError("Invalid S3 path. Path must start with 's3://'.")
# Remove 's3://' and split the remaining path
path_parts = s3_path[5:].split("/", 1)
# Bucket is the first part, prefix is the remaining
bucket = path_parts[0]
prefix = path_parts[1] if len(path_parts) > 1 else ""
return bucket, prefix
def delete_all_files(all_files):
logger = get_run_logger()
for file in all_files:
bucket, prefix = get_bucket_and_prefix(file)
logger.debug(f"Removing {file=}")
S3.delete_object(Bucket=bucket, Key=prefix)
def export_one_inventory(inventory, bucket, delete_files):
logger = get_run_logger()
all_files = get_all_files(inventory, bucket)
manifest_files = sorted([x for x in all_files if x.endswith("manifest.json")])
if len(manifest_files) == 0:
logger.warning(f"There are no manifests files for {inventory=}")
return False
for manifest_file in manifest_files:
reported_at = get_ts_from_manifest_path(manifest_file)
data_files = get_data_files_from_manifest(manifest_file)
read_and_export_data(inventory, bucket, data_files, reported_at)
if delete_files:
logger.info(f"Deleting {len(all_files)} files")
delete_all_files(all_files)
return True
@flow(name="export_inventory")
def export_all_inventories(flow_name="export_inventory", delete_files=False):
logger = get_run_logger()
for i, (inventory, bucket) in enumerate(INVENTORIES.items()):
percent = f"{i + 1}/{len(INVENTORIES)}"
logger.info(f"[Inventory {percent}] Processing {inventory=}'")
name = f"export_inventory.{inventory}__{percent}"
task(name=name)(export_one_inventory)(inventory, bucket, delete_files)
if __name__ == "__main__":
export_all_inventories()
Cleaning the Data with dbt
Below are the four models used to structure and clean the inventory data:
base_metadata__s3_inventory.sql: A base model for renaming and casting fields.clean_metadata__s3_inventory.sql: Ensures no duplicates and optionally keeps only the latest report.int_metadata__s3_inventory.sql: Tags paths for better categorization and insights.stg_metadata__s3_inventory.sql: Final staging model to remove temporary columns and select clean fields.
/models/staging/metadata/base/base_metadata__s3_inventory.sql
WITH source AS (
SELECT *
FROM {{ source('nt_bronze__metadata', 's3_inventory') }}
),
casted AS (
SELECT
---------- pks
's3://' || bucket || '/' || key AS s3_id,
---------- partitions
{{ from_iso_timestamp('p_extracted_at') }} AS p_extracted_at,
---------- info
bucket AS s3_bucket,
key AS s3_key,
lower(storage_class) AS storage_class,
---------- metrics
size / 1024.0 / 1024.0 AS size_mb,
---------- time related
last_modified_date AS last_modified_at,
reported_at
FROM source
)
SELECT *
FROM casted/models/staging/metadata/clean/clean_metadata__s3_inventory.sql
WITH source AS (
SELECT *
FROM {{ ref('base_metadata__s3_inventory') }}
),
latest_report AS (
SELECT
*,
{{ row_number('s3_id') }} AS _rn
FROM source
WHERE reported_at = (
SELECT MAX(t2.reported_at)
FROM source AS t2
WHERE t2.s3_bucket = source.s3_bucket
)
),
latest_data_from_latest_report AS (
SELECT *
FROM latest_report
WHERE _rn = 1
)
SELECT *
FROM latest_data_from_latest_report/models/staging/metadata/internal/int_metadata__s3_inventory.sql
-- Here we are categorizing differents paths with the `CASE WHEN s3_id LIKE pattern` so that we can better explore files.
-- Together with the `folders` columns they provide an excelent way to dig further into the costs.
{% set patterns = {
's3://ct-bronze-eu-west-1-742407267173-pro/%': 'tables/bronze',
's3://nt-data-engineering-eu-west-1-742407267173-pro/dbt/database/%': 'tables/de',
's3://nt-data-engineering-eu-west-1-742407267173-pro/dbt/staging_dir/%': 'temp/dbt_staging_dir',
's3://nt-data-engineering-eu-west-1-742407267173-pro/dbt/users/%': 'dbt_personal_schemas',
's3://nt-data-engineering-eu-west-1-742407267173-pro/s3_inventory/%': 's3_inventory',
's3://nt-data-engineering-eu-west-1-742407267173-pro/temp/%': 'temp/de_root'
} %}
WITH source AS (
SELECT *
FROM {{ ref('clean_metadata__s3_inventory') }}
), assigned_categories AS (
SELECT
*,
CASE
{% for path_pattern, category in patterns.items() -%}
WHEN s3_id LIKE '{{ path_pattern }}' THEN '{{ category }}'
{% endfor -%}
END AS _category,
CASE
{% for path_pattern, category in patterns.items() %}
WHEN s3_id LIKE '{{ path_pattern }}' THEN '{{ path_pattern }}'
{% endfor %}
END AS _path_pattern
FROM source
), extracted_folder AS (
SELECT
*,
COALESCE(_category, 'other') AS category,
CASE WHEN _path_pattern IS NOT NULL THEN
SPLIT_PART(SUBSTRING(s3_id, LENGTH(_path_pattern)), '/', 1)
END AS folder_1,
CASE WHEN _path_pattern IS NOT NULL THEN
SPLIT_PART(SUBSTRING(s3_id, LENGTH(_path_pattern)), '/', 2)
END AS folder_2
FROM assigned_categories
)
SELECT * FROM extracted_folder/models/staging/metadata/stg/stg_metadata__s3_inventory.sql
WITH source AS (
SELECT *
FROM {{ ref('int_metadata__s3_inventory') }}
),
selected_columns AS (
SELECT
---------- pks
s3_id,
---------- partitions
p_extracted_at,
---------- info
s3_bucket,
s3_key,
storage_class,
---------- metrics
size_mb,
---------- categories
category,
folder_1,
folder_2,
---------- time related
last_modified_at,
reported_at
FROM source
)
SELECT *
FROM selected_columns/models/staging/metadata/stg/stg_metadata__s3_inventory.yml
version: 2
models:
- name: stg_metadata__s3_inventory
description: >
Processes raw S3 inventory data, transforming it into a clean dataset
with partitioning, calculated metrics, and standardized fields for analysis.
columns:
# ---------- pks
- name: s3_id
description: Unique identifier for the S3 object in the format `s3://<bucket>/<key>`.
tests: [not_null, unique]
# ---------- partitions
- name: p_extracted_at
description: Partition column indicating when the metadata was extracted.
# ---------- info
- name: s3_bucket
description: The name of the S3 bucket containing the object.
- name: s3_key
description: The key (path) of the object within the bucket.
- name: storage_class
description: The storage class of the object, such as `standard`, `glacier`, etc., converted to lowercase.
# ---------- metrics
- name: size_mb
description: Size of the S3 object in megabytes, calculated as `size / 1024 / 1024`.
# ---------- categories
- name: category
description: >
High-level categorization of the S3 object based on its prefix,
such as `tables`, `code/dbt`, or `temp/de_root`.
- name: folder_1
description: The first folder level extracted from the S3 key after the matched path pattern.
- name: folder_2
description: The second folder level extracted from the S3 key after the matched path pattern.
# ---------- time related
- name: last_modified_at
description: Timestamp indicating when the object was last modified.
- name: reported_at
description: Timestamp indicating when the S3 inventory report was generated.Analyzing the Inventory
Once the data is consolidated in an Iceberg table, analysis can be customized based on your needs. Examples of what we analyzed:
- Categorizing Data: Analyze different categories of data.
- Exploring Folders: Dive into folder-level details for high-priority categories.
- Comparing Layers: Compare
bronzeandsilverlayers for the same entities to identify discrepancies.
Insights Gained
- Ineffective File Deletion: We found that files in our largest bucket were not being deleted effectively.
- Append-Only Tables: Some
bronzetables were only appending data without deletions, leading to unnecessary storage costs.
The first issue was addressed with an S3 Lifecycle Policy (details in the next section). The second issue, while significant, is beyond the scope of this post.
Implement S3 Lifecycle Policies
S3 Lifecycle Policies automate object management to reduce costs. For instance, you can transition objects to cheaper storage classes or delete non-current versions. Here’s how to set them up:
-
Navigate to Lifecycle Rules:
- In the S3 console, go to the Management tab of your bucket.
- Scroll to the Lifecycle Rules section and click Create Lifecycle Rule.
-
Define the Rule Scope:
- Provide a name for the rule.
- Specify whether the rule applies to the entire bucket or specific objects (e.g., those with a prefix or tag).
-
Configure Actions:
- Transition Actions: Move objects to cheaper storage classes like S3 Standard-IA, S3 Glacier Instant Retrieval, or S3 Deep Archive after a set number of days.
- Expiration Actions: Delete objects after a specified period.
- Non-Current Version Expiration: Remove older object versions in versioned buckets.
-
Review and Save:
- Review your configuration.
- Save it by clicking Create Rule.
Non-current version expiration is especially useful for buckets with versioning enabled to minimize storage costs.
By combining S3 Inventory with Lifecycle Policies, you can effectively analyze and manage your storage, ensuring optimal cost efficiency. This approach not only provides visibility into your data but also automates actions to keep your storage expenses under control.


