Prefect Essentials: Basics, Setup and Migration
- 2024-04-08
- 🛠️ Tools/Utils
- Tools Orchestration Intro Setup

0. Why Prefect?
Five years ago (in 2019), I created a pipeline to automate tasks (more info in Vtasks).
Initially, I used
Airflow (see how in
Setting up Airflow) since it was the industry standard at the time.
However, I found Airflow to be overly complex for my needs. This led me to switch to
Luigi (see how in
Luigi orchestrator).
While Luigi worked better for me, I still lacked features such as dynamic DAG creation based on input parameters.
Fortunately, I discovered Prefect, which offered the simplicity and flexibility I desired:
- Super simple to start with
- Very flexible
I quickly adopted Prefect for my pipeline and found it to be highly effective.
You might be hesitant to use a new tool without substantial support. However, Prefect is gaining popularity and is positioned as the top Airflow alternative, as evident from the GitHub stars of various orchestrators:
GitHub Stars extracted using Daily Stars explorer.
To quickly see the star history of a repo, you can use
Stars History.
1. Prefect Basics
If you want a more in-depth introduction to Prefect basics, you can read Prefect Quickstart instead.
The first step is to install prefect with:
pip install prefect1.1. First flow (aka DAG)
Now, you’re ready to create your first flow (this is how Prefect refers to a DAG) using a simple decorator:
/main.py
from prefect import flow
@flow
def greet(name):
print(f"Hello {name}")
if __name__ == '__main__':
greet("John")To run the flow, execute the following command:
python main.py1.2. Adding tasks and subflows
In Prefect, you can add tasks to be run inside a flow.
Tasks work similarly to flows since they are also defined with a decorator:
/main.py
from prefect import flow
from prefect import task
@task
def greet(name):
print(f"Hello {name}")
@flow
def good_morning():
greet("John")
greet("Sam")
if __name__ == '__main__':
good_morning()A flow can call another flow, and you can have as many layers as you want of flows calling flows inside them.
So you could change the code above to:
from prefect import flow
@flow # Now this is a flow
def greet(name):
print(f"Hello {name}")
@flow
def good_morning():
greet("John")
greet("Sam")
if __name__ == '__main__':
good_morning()A task cannot call another task inside itself.
1.3. Using tags
Adding tags in Prefect is quite straightforward:
from prefect import tags
with tags("env:pro", "type:greet"):
good_morning() # Call any 'flow' you wantThe tags are simply strings.
In order to categorize, I like to use tags with {key}:{value} format, like env:pro.
This helps me to later filter flows.
1.4. Adding logs
To add logs linked to Prefect you need to:
from prefect import flow
from prefect import get_run_logger
@flow(name="greet")
def greet(name):
logger = get_run_logger()
logger.info(f"Hello {name}")
if __name__ == '__main__':
greet("John")get_run_logger() must be called inside a task or a flow, else it will fail.
Also, notice that in this example, I defined a name for the flow.
2. Connection to Prefect Cloud
With the example we did Prefect run locally with a local database it created. This is useful for testing but you shouldn’t be running jobs in production without a server.
To connect to Prefect cloud you can do it with:
prefect cloud loginThis will open an internet window where you will be asked to log in. Since this won’t work well on automated processes, the alternative is to create a Prefect token:
prefect cloud login -k your_tokenMake sure to replace your_token. Prefect tokens usually start with pnu_.
In some cases, you might run into problems because Prefect is still using the default settings. To clean them out, go to ~/.prefect and delete the files that are there.
Important: this will delete the local database with the information of the flows you just ran.
3. Using Prefect Blocks
You can use Prefect Blocks to set up connections to external tools.
For example, you can use the Slack Block to store a Slack webhook.
Once done, you can send Slack messages by simply running:
from prefect.blocks.notifications import SlackWebhook
slack_webhook_block = SlackWebhook.load("slack") # The name of the block you just created
slack_webhook_block.notify("Hello from Prefect!")4. Naming conventions
When calling flows or tasks, I like to follow a naming convention where each unit inherits a prefix from its parent. In the example we used before, it would be:
from prefect import flow
@flow(name="good_morning.greet")
def greet(name):
print(f"Hello {name}")
@flow(name="good_morning")
def good_morning():
greet("John")
greet("Sam")
if __name__ == '__main__':
good_morning()This helps keep things organized and makes it easier to understand the relation between different flows and tasks.
For a more complex example, let’s take a look at my personal pipeline Vtasks.
There we can see how the main flow
vtasks calls different flows like vtasks.backup or vtasks.expensor.
They in turn have different tasks inside:
- vtasks
├── vtasks.backup
│ ├── vtasks.backup.backup_files
│ ├── vtasks.backup.clean_backups
│ └── vtasks.backup.copy
├── vtasks.expensor
│ ├── vtasks.expensor.read
│ └── vtasks.expensor.report
└── ...5. Migrating to prefect
I think that migrating from another orchestrator to Prefect can be easily done in incremental steps:
- Track executions
- Set up a Prefect Server (this is optional, you can use Prefect cloud instead)
- Create deployments so that you can trigger executions from Prefect
- Schedule flows with Prefect
The idea behind those steps is to be able to test Prefect and see if it indeed suits your needs better compared to other solutions.
5.1. Track executions with prefect
This first step towards implementing Prefect is to add some flows in any Python code you have. The idea is to use Prefect only for observability purposes so that you have a centralized place from where you can:
- See logs
- Track flows/tasks outcomes
- Have notifications for failures
This won’t interfere with any existing orchestrator.
So for example let’s imagine that you use Airflow for triggering EMR jobs. Here what you would do is to add Prefect decorators to the code that runs in EMR.
For example you could have the following flows:
- my_emr_job
├── my_emr_job.read
├── my_emr_job.transform
│ ├── my_emr_job.transform.rename
│ └── my_emr_job.transform.cast
└── my_emr_job.writeThis is just a dummy example but it helps to illustrate how you could add better observability.
5.2. Set up a Prefect server
At this point, you will need to decide if you want to set up your Prefect server.
If you want to do so you can read how in Prefect Server Setup: Configuration and Deployment.
You can always start creating your Prefect server and then migrate to Prefect cloud or the other way around.
5.3. Create deployments for running flows
In this step, you will create Deployments for the flows you want to be able to trigger from Prefect.
This will allow you to perform backfills or any other manual run using Prefect UI.
Again, this won’t interfere with any existing orchestrator.
It will only provide another way of manually triggering flows.
As an example, see how you can use dropdowns, date pickers, default values and other nice features that simplify triggering manual runs:
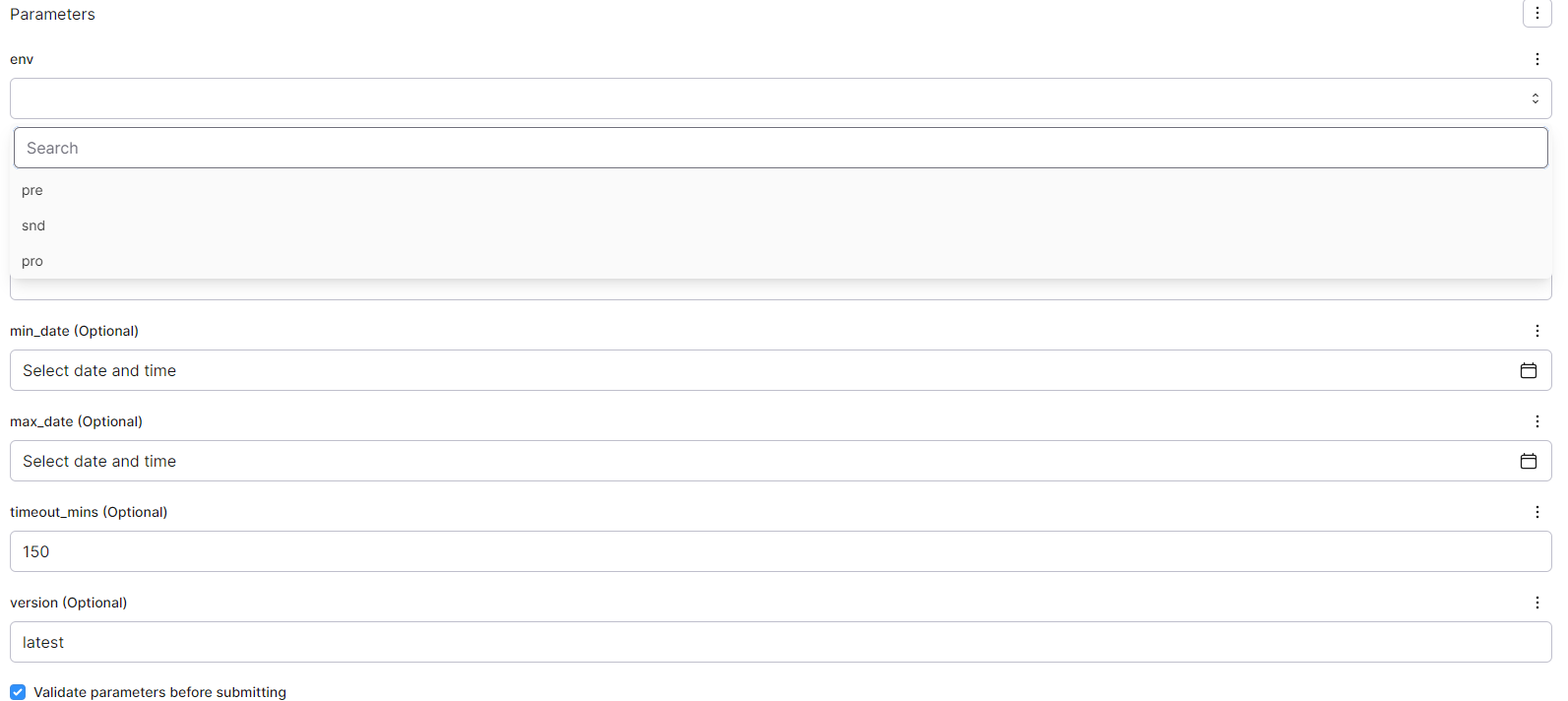
This is automatically created as long as you properly define the parameters in your flow. This is the code for the example above:
from datetime import datetime
from typing import Literal
@flow(name="prefect.emr.salesforce.sf_export")
def sf_export(
env: Literal["pre", "snd", "pro"],
select: str = None,
exclude: str = None,
min_date: datetime = None,
max_date: datetime = None,
timeout_mins: int = 150,
version: str = "latest",
):In order to see how to create the Deployments themselves, read Prefect Server Setup: Configuration and Deployment | Deployments
5.4. Schedule flows with prefect
The last step is to finally use Prefect for scheduling the flows.
Now is the time to finally switch to Prefect and to deprecate any other orchestrator you might have.
To see how to schedule flows, go to Prefect Server Setup: Configuration and Deployment | Deployments
6. Using prefect.client
We can use prefect.client to interact with the Prefect API.
This allows us to do very powerful things like:
- Updating tags at runtime based on input parameters
- Querying past flows and taking certain actions based on the outcome
All interactions with prefect.client are async.
That means you will need to do one of the following:
- Defining
asyncfunctions whenever interact with it - Calling
asyncio.run()(orawaitif you are in a Jupyter Notebook)
6.1. Updating tags at runtime
In general tags are defined prior to a flow_run.
However, it is possible to modify those tags at runtime.
This is very useful to add tags based on the input parameters of a flow.
Imagine that we have a flow that can run in pre/pro, it is really useful to tag the flow_run with the environment where it ran.
We can update the tags with the following code:
import asyncio
from prefect import get_run_logger
from prefect.client import get_client
from prefect.context import get_run_context
def update_tags(tags):
logger = get_run_logger()
if not tags:
logger.warning("No tags passed to 'update_tags', nothing to do")
return True
logger.info(f"Adding {tags=} to current flow_run")
# Read current flow
flow_run = get_run_context().flow_run
tags += flow_run.tags
client = get_client()
asyncio.run(client.update_flow_run(flow_run.id, tags=set(tags)))
return True
This is meant to be called from a flow. It won’t work if called from a task.
And then we would use it with:
from prefect import flow
@flow(name="good_morning.greet")
def greet(name):
print(f"Hello {name}")
@flow(name="good_morning")
def good_morning(env):
update_tags([f"env:{env}"])
greet("John")
greet("Sam")
if __name__ == '__main__':
good_morning("pro")6.2. Querying prefect for conditional flows
You can query any prefect entity with the prefect.client like:
flowsflow_runstasks
For example for querying flow_runs we would use something like:
from prefect.client import get_client
from prefect.client.schemas import filters
from prefect.client.schemas import sorting
async def read_flow_runs(flow_run_filter=None, sort=sorting.FlowRunSort.START_TIME_DESC):
"""
Asynchronously retrieves flow runs with query limits.
Args:
offset (int): Offset for paginating the results.
flow_run_filter (prefect.client.schemas.filters.FlowRunFilter, optional): Filter for flow runs. Defaults to None.
sort (prefect.client.schemas.sorting.FlowRunSort, optional): Sorting options. Defaults to sorting.FlowRunSort.START_TIME_DESC.
Returns:
list: List of flow runs.
"""
client = get_client()
return await client.read_flow_runs(flow_run_filter=flow_run_filter, sort=sort)We can use the flow_run_filter to filter the flow_runs we want to get.
It is a little bit complex since you need to use the filter from prefect.client.schemas.
For example:
async def query_flow_runs(name_like, env, state_names, start_time_min)
filter_params = {
"name": filters.FlowRunFilterName(like_=name_like),
"tags": filters.FlowRunFilterTags(all_=[f"env:{env}"]),
"state": filters.FlowRunFilterState(
name=filters.FlowRunFilterStateName(any_=state_names)
),
"start_time": filters.FlowRunFilterStartTime(after_=start_time_min),
}
flow_run_filter = filters.FlowRunFilter(**filter_params)
return await read_flow_runs(flow_run_filter)Finally with that we can use that to see if we have already run a flow with:
from datetime import datetime, timedelta
flow_runs = asyncio.run(
query_flow_runs(
name_like="vtasks.gcal.summary",
env="pro",
start_time_min=datetime.now() - timedelta(days=1)
)
)
if flow_runs:
do_something()This is very useful when you have a pipeline that executes multiple times a day and you don’t want to run a flow/task each time but only once if it hasn’t been done in less than a day.
6.3. Cancelling Stuck Flow Runs
Occasionally, flow runs may appear as Running even when they are not.
This can happen, for example, when an EMR job times out.
To address this, the first step is to retrieve the running flow runs:
from datetime import datetime, timedelta
import pandas as pd
from prefect import states
from prefect.client import get_client
from prefect.client.schemas import filters
from prefect.client.schemas import sorting
client = get_client()
async def get_running_flow_runs(start_time_min=datetime.now() - timedelta(days=1)):
filter_state = filters.FlowRunFilterState(
name=filters.FlowRunFilterStateName(any_=["Running"])
)
filter_start_time = filters.FlowRunFilterStartTime(after_=start_time_min)
data = await client.read_flow_runs(
flow_run_filter=filters.FlowRunFilter(state=filter_state, start_time=filter_start_time),
sort=sorting.FlowRunSort.START_TIME_DESC
)
return pd.DataFrame([x.dict() for x in data])This function will provide you with a pandas dataframe containing all the running flow runs.
You may not want to cancel all running flow runs, so be sure to filter them accordingly.
Next, you can cancel the flow runs with the following code:
async def cancel_flow_runs(flow_run_ids):
for flow_run_id in flow_run_ids:
await client.set_flow_run_state(str(flow_run_id), state=states.Cancelled(), force=True)
df = await get_running_flow_runs()
await cancel_flow_runs(flow_run_ids=df["id"])This script will cancel the flow runs that are stuck in the Running state.



