
Motivation
In traditional pipelines, data processing typically focuses on the last batch, such as yesterday’s data for daily executions. While effective under normal circumstances, multiple failures can lead to tedious backfilling processes. This post delves into the concept of self-healing pipelines, which streamline operations by automatically backfilling failed executions, reducing the need for manual interventions.
Regular batch processing
Let’s imagine you have a daily pipeline that was running well until Friday (2024-05-03) when someone pushed a bug to production.
You discover the mistake on Monday (2024-05-06) morning.
Now you need to recover all missing data, which means you need to backfill 3 days.
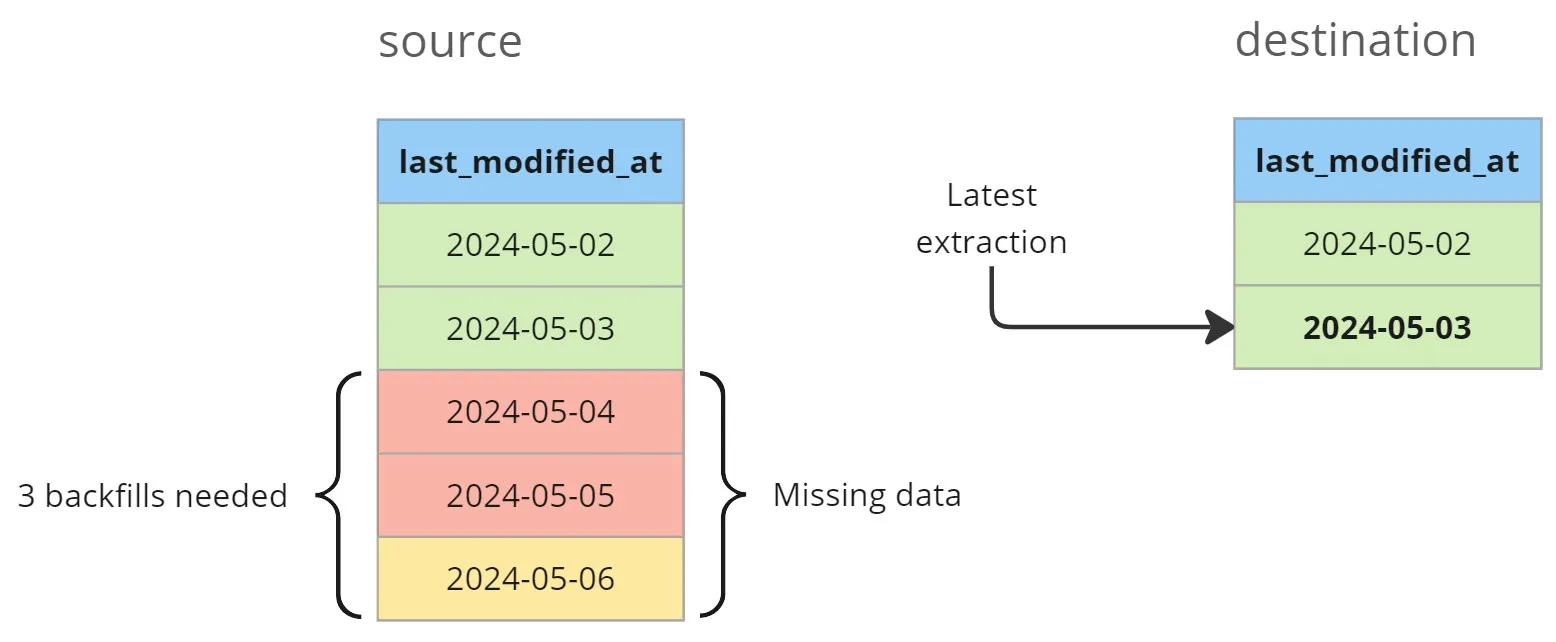
To address this issue, you manually schedule three jobs in your orchestrator, each tasked with extracting the missing data for a specific day. However, this approach has some limitations:
- Manual Intervention: Backfilling requires manual intervention to schedule the jobs, which can be time-consuming and prone to errors.
- Cost Considerations: Running three separate jobs for each day can be less cost-effective, especially in systems like Spark, where spinning up multiple jobs incurs additional overhead.
Processing new data
The concept of Self-healing pipelines revolves around processing data that is newer than the last successful extraction performed.
In essence, the pipeline automatically identifies and handles data gaps or discrepancies by processing only the most recent data.
Here’s the logic in pseudo code:
source.last_modified_at > max(destination.last_modified_at)In simpler terms, the pipeline extracts data from the source if its last modification timestamp is greater than the maximum last modification timestamp in the destination.
In the scenario described earlier, where the last correct extraction was performed on 2024-05-03, the next run of the pipeline would process data from that date up until 2024-05-06.
Important: When processing a large number of days, it may be necessary to allocate additional resources. Moreover, automatic scaling of resources might be required for seamless operation.
Partitioning
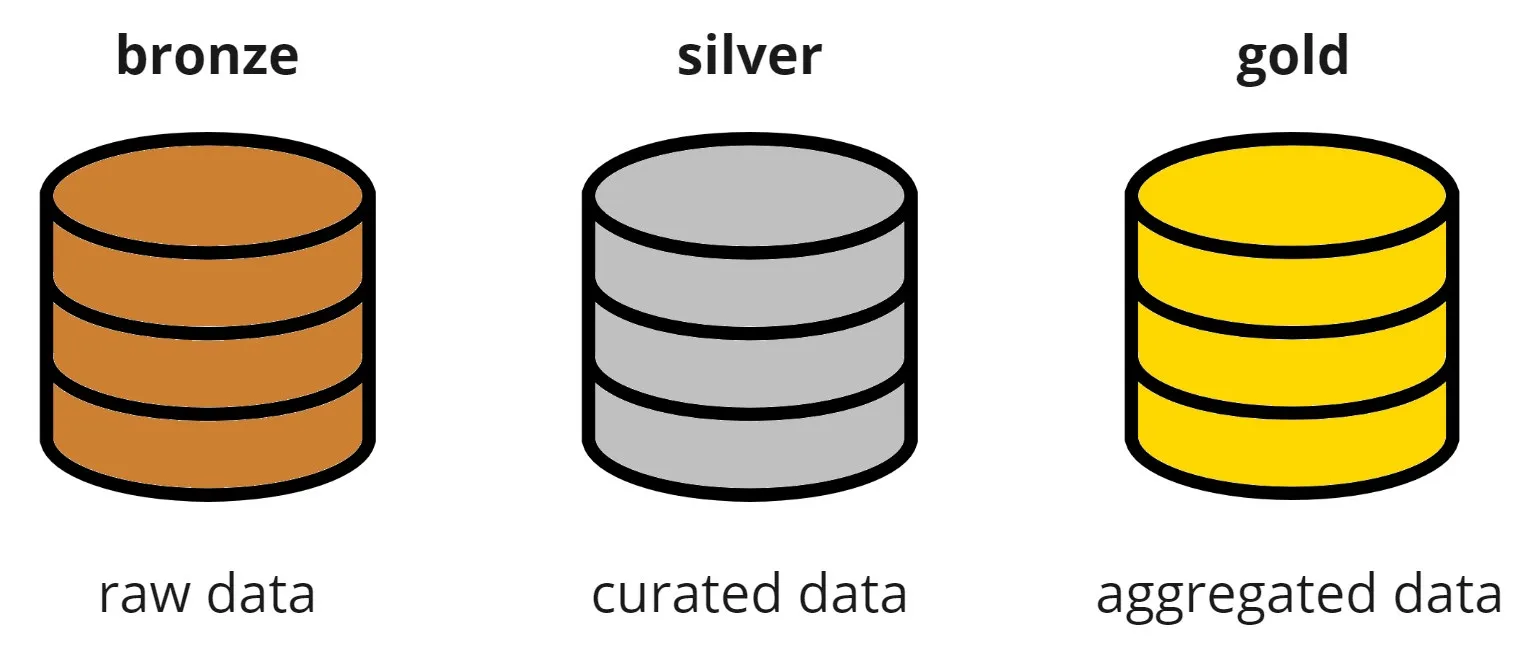
Partitioning the data lake into three layers, as recommended by Databricks in their Medallion Architecture, provides a structured approach to data management. Here are the layers:
- Bronze: Also known as
raworlanding, this layer contains the data in its original form, without any transformations. It serves as the initial landing place for all incoming data. - Silver: The silver layer involves processing and cleaning the data from the bronze layer. Here, data quality checks and transformations are performed to prepare the data for further analysis.
- Gold: The gold layer represents the refined and curated data that is optimized for consumption by end-users or downstream applications. This layer typically contains aggregated, enriched, and business-ready datasets.
Partitions in bronze
Partitioning the bronze layer by the extraction datetime, typically labeled as p_extracted_at, offers several advantages:
- Avoidance of rewriting old partitions: New data extractions can be appended without the need to update or rewrite existing partitions. This simplifies data ingestion and reduces the risk of inadvertently modifying historical data.
- Facilitation of tracking: The partition column provides clear visibility into when the last extraction occurred and identifies which data needs processing. This makes it easier to monitor data freshness and manage incremental processing workflows effectively.
Partitions on silver/gold
Then on silver and/or gold layers you can switch to partition by creation_date (based on the data) or to not partition at all.
As a reference see When to partition tables on Databricks.
They suggest that you only partition big tables (> 1TB) when using delta tables (also applicable to iceberg or hudi tables).
So on those layers you will need to read all new partitions from bronze and update that table on silver/gold.
The easiest way is to use the MERGE INTO option that both Delta Lake and Iceberg support.
Deduplication
In the bronze layer, where data extraction occurs, partitioning by p_extracted_at is essential for efficient data management. However, this partitioning strategy can lead to duplicates when processing multiple bronze partitions. To address this issue, we implement deduplication by retaining only the latest entry for each unique identifier (id).
As an example, let’s imagine the following data:
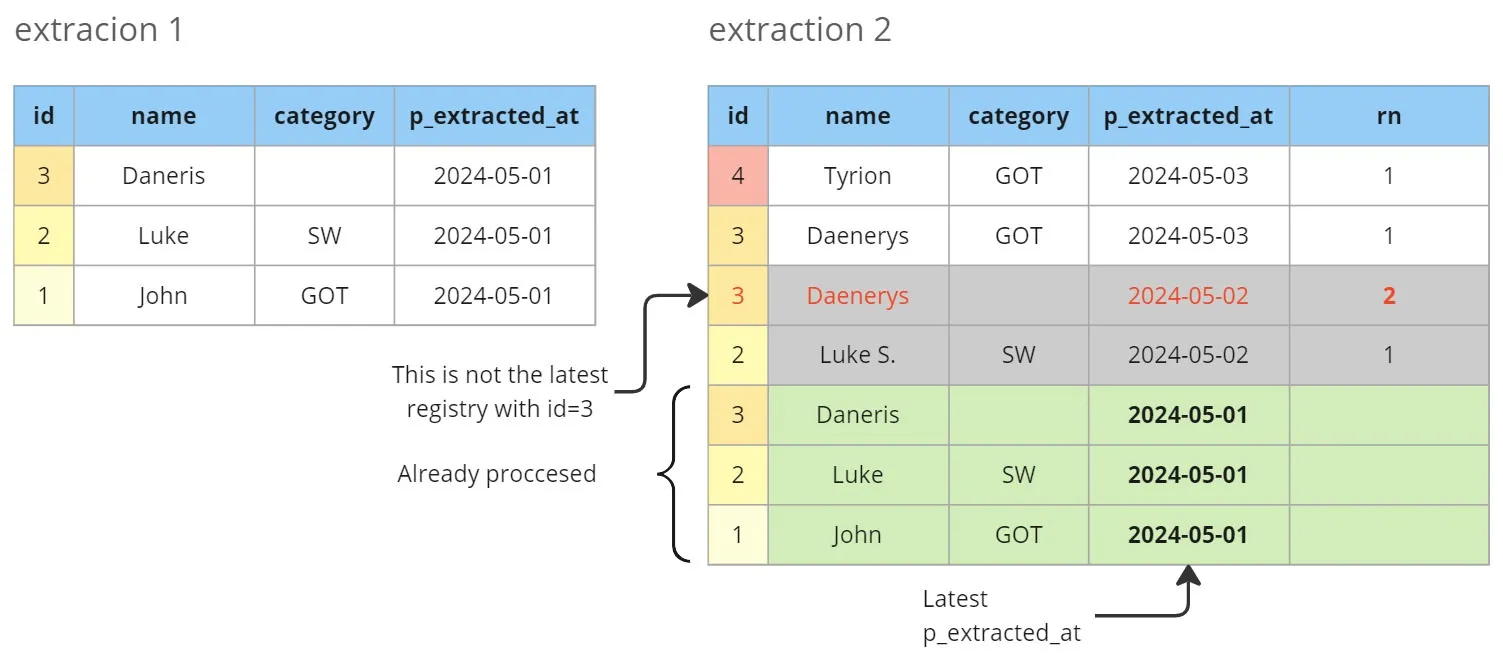
Here’s an overview of the deduplication process:
- Identify unique rows: Use the
row_number()function to assign a sequential number (rn) to each row within a partition, ordered by thelast_modified_atfield (orp_extracted_atiflast_modified_atis unavailable). This function is applied in descending order, ensuring that the latest entry for eachidreceivesrn = 1. - Filter duplicates: Keep only the records where
rn = 1, as they represent the latest version of each unique identifier. Discard any rows withrn > 1, as they are duplicates.
Deduplication when there is no id column
If there is no id column, you will need to create one.
This is done by creating a composite key as described in dbt | Composite key.
The easiest way to do so in dbt is by using the dbt_utils.generate_surrogate_key macro.
More info at dbt | SQL surrogate keys.
That can easily be replicated in python or other programming languages.
Code snippets
Now that we have all the concepts clear, let’s see how to implement it in python and SQL.
Python
I use spark with python for extracting data for new sources.
The important part here is to:
- Get the
max_datetime - Extract new data based on
max_datetime - Export it partitioned by
p_extracted_at
Get max_datetime
from datetime import datetime
from datetime import timedelta
from dateutil import parser
from loguru import logger # or any other logger
PARTITION_COL = "p_extracted_at"
def table_exists(spark, tablename: str, db=None):
"""Checks if a table exists"""
# Check and extract proper 'db' and 'tablename'
if db is None:
msg = "'tablename' must be like 'db.table' or 'iceberg.db.table' when db=None"
if tablename.startswith("iceberg."):
assert len(tablename.split(".")) == 3, msg
db, table = tablename.split(".")[-2:]
else:
assert len(tablename.split(".")) == 2, msg
db, table = tablename.split(".")
else:
msg = "When passing 'db' then 'tablename' cannot have a '.'"
assert "." not in tablename, msg
table = tablename
return spark.sql(f"SHOW TABLES IN {db} LIKE '{table}'").count() > 0
def infer_max_datetime(
spark,
tablename,
filter_col,
lookup_days=7,
partition_col=PARTITION_COL,
as_datetime=True,
):
"""
Infers the 'max_date' of a table by checking the greater value inside the table.
"""
logger.info(f"Infering 'max_date' for '{tablename}' ({filter_col=})")
if not table_exists(spark, tablename):
logger.warning(
f"Table '{tablename}' does not exist which should only happen at the first run."
)
return None
min_partition = (datetime.now() - timedelta(days=lookup_days)).isoformat()
logger.info(f"Querying with {min_partition=}")
sdf = spark.table(tablename).filter(f"'{partition_col}' >= '{min_partition}'")
min_dt_str = sdf.agg({filter_col: "max"}).collect()[0][0]
logger.info(f"Infered {min_dt_str=}")
if not min_dt_str:
logger.warning(f"max('{filter_col}') returned no values")
return None
if as_datetime:
min_dt = parser.parse(min_dt_str)
logger.info(f"Infered {min_dt=} for '{tablename}'")
return min_dt
return min_dt_strNotice that here we are querying a column filter_col (which usually will be last_updated_at).
Given that the pipeline can fail and/or that we can do backfills, that max value might not be in the latest partition.
This is why I recommend querying N days of data (7 by default) and getting the max from there.
Extract new data and store it
from datetime import datetime
from pyspark.sql import SparkSession
from pyspark.sql import functions as F
PARTITION_COL = "p_extracted_at"
TABLENAME = "db.table"
def main():
spark = SparkSession.builder.appName("test").getOrCreate()
# Get the max `last_updated_at`
max_dt = infer_max_datetime()
# Extract new data
sdf = get_data(where=f"WHERE last_updated_at >= {max_dt}")
# Add partition column
sdf = sdf.withColumn(PARTITION_COL, F.lit(datetime.now().isoformat()))
# Write the data
sdf.write.mode("append").format("parquet").saveAsTable(TABLENAME)
spark.stop()
if __name__ == '__main__':
main()get_data is not defined since it’s out of scope.
It’s just a function that queries some external system.
dbt (SQL)
I use dbt for transforming and creating the silver and gold layers.
Those examples should explain how to:
- Process only new data
- Deduplicate
dbt macros
With dbt, I like to define 2 macros:
row_number. This is useful because in most tables I sort the windows with the same ways and I use the same key.last_update. This one is useful for getting the latest update of the ‘self’ table (thisin dbt).
They can be defined with:
{%- macro row_number(keys='id', sorting='p_extracted_at DESC') -%}
ROW_NUMBER() OVER(PARTITION BY {{ keys }} ORDER BY {{ sorting }})
{%- endmacro -%}
{%- macro last_update(column, filter_expression=None, table=this) -%}
(
SELECT max({{ column }})
FROM {{ table }}
{%- if (filter_expression) -%}
WHERE {{ filter_expression }}
{%- endif -%}
)
{%- endmacro -%}And the documentation:
version: 2
macros:
- name: row_number
description: Gets the row_number which will be used for removing duplicates
arguments:
- name: keys
type: string
description: Column(s) used to define table unicity. Default `id`
- name: sorting
type: string
description: Column and direction used to sort the window. Default `p_extracted_at DESC`
- name: last_update
description: |
Returns the **last_update** from the `self` table.
This is useful for building smart incremental models where we only process the deltas that are not processed.
It would be used like:
SELECT *
FROM source
{% raw %}{% if is_incremental() -%}
WHERE p_extracted_at > {{ last_update('_extracted_at') }}
{%- endif %}{% endraw %}
arguments:
- name: column
type: string
description: Name of the column that contains the `last_update`dbt model
Once you have the macros, the basic code for the model would look like:
WITH source AS (
SELECT *
FROM {{ ref('your_source_table') }}
),
latest_data_from_source AS (
SELECT
*,
{{ row_number() }} AS rn
FROM source
{% if is_incremental() -%} -- This helps reading only the new data
WHERE p_extracted_at > {{ last_update('_extracted_at') }}
{%- endif %}
),
deduplicated AS (
SELECT
---------- ids
id,
---------- add any other column here
other_column
---------- metadata
p_extracted_at AS _extracted_at
FROM latest_data_from_source
WHERE rn = 1 -- This is for deduplication
)
SELECT *
FROM deduplicatedIt’s important that you set the proper materialization.
In general, it should be materialization=incremental (see: dbt | Incremental models).
And you might also need to set up the incremental strategy. For example, with dbt Athena I set the incremental_strategy: merge and the table_type: iceberg.
Handling schema changes
One last thing you might want to automatically handle are schema changes. You cannot handle all of them but you can easily adapt to:
- Missing columns
- New columns
- Types changed
I only suggest you do that on bronze where you want to have as fewer errors as possible.
Notice that if you implement some automatic handling of schema changes you might have inconsistent data that you will need to handle. Do it at your own risk.
New or missing columns
If you want to automatically handle missing columns, you simply need to add them as NULL in the input dataframe.
When working with Delta or Iceberg, you can easily add columns without problems.
But sometimes on the bronze you might be working with raw parquet.
In that case, you will need to manually add the column to the catalog.
You can do both things with the following code:
def fix_missmatching_columns(spark, sdf, tablename):
if not table_exists(spark, tablename):
logger.warning(
f"'{tablename}' doesn't exist which should only happen at the first run"
)
return sdf
sdf_hist = spark.table(tablename)
# Get columns from the parquet table and current dataframe
columns_history = sdf_hist.columns
columns_current = sdf.columns
# See which ones are missing and the new ones
columns_new = set(columns_current) - set(columns_history)
columns_missing = set(columns_history) - set(columns_current)
if columns_new:
cols_to_add = [f"{x} {get_col_dtype(sdf, x)}" for x in columns_new]
cols_text = ", ".join(cols_to_add)
logger.info(
f"Adding to '{tablename}' [source] {len(columns_new)} "
f"new columns: {cols_to_add=}"
)
spark.sql(f"ALTER TABLE {tablename} ADD columns ({cols_text})")
if columns_missing:
cols = {x: get_col_dtype(sdf_hist, x) for x in columns_missing}
logger.warning(
f"There are {len(columns_missing)} missing columns in "
f"'{tablename}' [sdf]: {cols=}. Adding them as `NULL`."
)
sdf = sdf.select(
"*",
*[F.lit(None).cast(dtype).alias(name) for name, dtype in cols.items()],
)
if not columns_new and not columns_missing:
logger.debug(f"Columns match for '{tablename}'")
return sdfHandling type changes
If you experience multiple type changes in your tables and you want to automatically handle them, I think that the best thing you can do is to convert all columns to string.
Then on the silver layer, you can apply the proper type you want by casting.
This should ensure that you always extract data to bronze no matter what.


