Improving Athena performance by reducing Glue versions
- 2025-04-10
- ⚙️ DE
- DE AWS Best Practices Performance DBT Glue

0. What happened?
We hit a strange issue with dbt Athena where no queries were running:

After digging we discovered the culprit: Glue table version limits.
Until then, I was totally unaware that:
- There is a hard limit of 1 000 000 schema versions across the entire Glue catalog.
- Exceeding this limit doesn’t just block updates — it breaks Athena queries in ways that aren’t obvious.
Glue has a hard limit of 1 000 000 schema versions across the entire Glue catalog.
1. Glue versions
Almost all the tables we write are Iceberg, which manages schema evolution more effectively under the hood. From an Iceberg perspective, we don’t need Glue versioning at all — it’s a side effect of using Glue as a catalog.
We use Glue only as a metadata catalog. We do not use Glue ETL jobs — in our experience, there are far better tools for orchestration and transformation.
Today, our tables are written using a mix of Spark, AWS Wrangler, and dbt. Each of these interacts with Glue differently when it comes to table updates and schema registration.
We’ll show the number of versions grouped by writer:

Most of the version bloat came from AWS Wrangler and Spark in our case. These tools often update or overwrite tables in ways that trigger new Glue versions automatically — and frequently.
In our case:
- We had 4,429 tables before cleanup.
- Some of these tables had thousands of versions.
- We weren’t explicitly managing schema evolution — just running pipelines.
The version bloat was entirely invisible… until it wasn’t.
1.1. Glue versions in dbt
On the dbt side, the impact was smaller — but not zero.
We’re mostly using materialized = table, which means dbt recreates the table entirely on each run. This avoids version accumulation because Glue treats each run as a clean slate.
However, views are a different story. Since they’re not dropped and recreated, each run updates the definition, which adds a new Glue version every time.
dbt does support version cleanup using the expire_glue_table_versions macro, and you can configure how many versions to keep using the versions_to_keep parameter (see DBT Athena config | High availability for more info).
This is especially useful when working with incremental Iceberg models or when using Hive tables with high availability (HA) — the two cases where Glue version bloat can accumulate rapidly. By default, versions_to_keep is set to 4, but this can be customized.
Even with dbt, Glue version bloat can sneak in — especially with views, incremental Iceberg models or hive tables with high availability.
In our case, it’s not needed because we use materialized = table, so our tables are fully recreated on each run, avoiding accumulation.
So while dbt wasn’t the main contributor to version bloat, it still affected our total version count through view models.
2. How to clean old versions
I wrote a script that:
- Iterates over all databases
- Iterates over all Glue tables
- Lists all versions
- Keeps only the latest few
- Deletes the rest using
boto3
This brought the catalog size down massively:
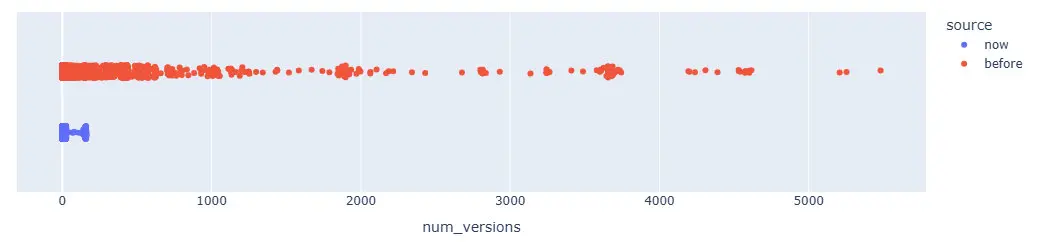
I counted the versions in the before scenario after deleting a lot of glue versions.
This is because first I unblocked the production pipeline, then I took some time to analyze it properly.
We can also visualize it with a distribution plot:
The canvas above is a smoothed version of the raw version count data for readability.
| metric | before | now |
|---|---|---|
| total tables | 4429 | 4760 |
| total versions | 657129 | 54745 |
This is a 92% reduction in Glue versions.
You might wonder why we still have an average of ~100 versions per table. That’s because:
- Some tables are written to hourly
- Our cleanup job runs weekly
- The snapshot was taken a few days after the last cleanup
Here’s the full code we used, broken down in sections:
2.1. Getting database and tables info
from datetime import datetime, timedelta, timezone
import awswrangler as wr
import boto3
import botocore
from loguru import logger
DB_DEFAULT = "default"
MIN_VERSIONS = 5
RETENTION_DAYS = 14
def get_databases(limit=1000):
logger.info(f"Getting all databases ({limit=})")
df = wr.catalog.databases(limit=limit)
logger.info(f"There are {df.shape[0]} databases")
return df["Database"].to_list()
def get_tables(database, limit=1000):
logger.info(f"Getting all tables in {database=} ({limit=})")
df = wr.catalog.tables(database=database, limit=limit)
logger.info(f"There are {df.shape[0]} tables in {database=}")
return df["table"].to_list()
def get_versions(database, table, client=None):
client = client or boto3.client("glue")
paginator = client.get_paginator("get_table_versions")
out = []
for data in paginator.paginate(DatabaseName=database, TableName=table):
out += data["TableVersions"]
return out
2.2. Cleaning versions of a table with batches
def _chunked(iterable, size):
"""Yield successive chunks from iterable of given size."""
for i in range(0, len(iterable), size):
yield iterable[i : i + size]
def clean_old_glue_table_versions(database, table, min_versions, retention_days):
cutoff_date = datetime.now(timezone.utc) - timedelta(days=retention_days)
prefix = f"Table '{database}.{table}'"
client = boto3.client("glue")
versions = get_versions(database, table, client=client)
versions = sorted(versions, key=lambda v: v["Table"]["UpdateTime"])
if len(versions) <= min_versions:
logger.debug(f"{prefix} has {len(versions)} versions < {min_versions=}, nothing to do")
return 0
logger.debug(f"{prefix} has {len(versions)} versions")
old_versions = []
for v in versions:
created = v.get("Table", {}).get("UpdateTime")
if created and created < cutoff_date:
old_versions.append(v)
if len(old_versions) <= min_versions:
logger.debug(
f"{prefix} has {len(old_versions)} versions older "
f"than {retention_days=} < {min_versions=}, nothing to do"
)
return 0
delete_versions = old_versions[:-min_versions]
logger.info(
f"{prefix} has {len(old_versions)} versions older "
f"than {retention_days=}, deleting {len(delete_versions)}"
)
version_ids = [x["VersionId"] for x in delete_versions]
for chunk in _chunked(version_ids, 100):
client.batch_delete_table_version(
DatabaseName=database, TableName=table, VersionIds=chunk
)
return len(version_ids)
2.3. Cleaning the whole catalog
def clean_one_database(database, min_versions, retention_days):
tables = get_tables(database)
logger.info(f"Processing {database=} with {len(tables)=}")
n_deletes = 0
for table in tables:
try:
n_deletes += clean_old_glue_table_versions(
database, table, min_versions, retention_days,
)
except botocore.exceptions.ClientError as e:
if e.response["Error"]["Code"] == "EntityNotFoundException":
logger.warning(f"Table '{database}.{table}' not found, skipping it")
else:
raise # Re-raise unknown errors
logger.info(f"{database=} done with {n_deletes=}")
return n_deletes
def process(min_versions=MIN_VERSIONS, retention_days=RETENTION_DAYS):
databases = get_databases()
total_deletes = 0
for i, database in enumerate(databases):
logger.info(f"[Database {i + 1}/{len(databases)}] Processing {database=}")
total_deletes = clean_one_database(database)
logger.info(f"{len(databases)} databases proccessed with {total_deletes=}")
3. Performance gains
What surprised us the most was that Athena performance improved dramatically, even though dbt wasn’t contributing much to the version bloat.
We suspected the performance hit came from Glue metadata overhead during query planning — and cleaning up versions helped significantly.
Our main pipelines became faster:
- Daily: 2× faster (from 2h to 1h)
- Hourly: 4× faster (from 64min to 16min)
Even if you use dbt and aren’t generating many Glue versions, it’s worth checking. After reducing the catalog size, we saw up to 4× faster execution in Athena.
4. Takeaways
- Be aware of the 1 000 000-version hard limit in the Glue Catalog — it’s not just theoretical.
- If you’re using Spark, or AWS Wrangler to write tables, version bloat is almost guaranteed.
- Neither Glue nor Athena will warn you — you have to monitor and manage it proactively.
- Cleaning up old schema versions doesn’t just avoid failures — it can lead to significant performance gains.
We’ve now automated this cleanup as a regular maintenance task.



